数据库并发控制相关的一些问题和总结
最近在研究数据库事务和并发控制,主要的学习资料是《数据库系统概念 第六版》。本文记录了一些自己的理解和问题。如果同样在看这本书或者在研究类似问题的有兴趣可以看一下。这本书描述的东西比较理论,但是对数据库的各种问题的描述比较深入,相比网上的一些文章更加能接触到「真正的东西」,比较推荐。
一些待解决的问题
为什么需要设计共享锁和排他锁?还有意向锁。
SELECT * FROM child WHERE id = 100;If id is not indexed or has a nonunique index, the statement does lock the preceding gap.
为什么这种语句需要加间隙锁?没道理啊 …
答:光 select 是不加锁的,select for update 或者加共享锁才会。光 select 会直接读 MVCC 的快照。
各种锁是如何被数据库系统使用的,如何用锁解决了数据库的一致性和隔离性要求
答:锁锁住了数据,避免了并行执行事务之间的冲突。
锁的目的:是为了实现并发事务控制。各种锁:行锁、间隙锁、next-key 锁。
事务的隔离性和并发
事务要求能并发执行。并发执行不同于顺序执行,会产生数据的一致性问题。所以又要求事务并发执行时能够互相隔离,避免各种冲突和其他问题而导致的数据的不一致。
事务的隔离性是通过并发控制器(concurrency-control)来实现的。他控制着并发事务的执行,可以让并发执行的事务就像串行执行一样,能保证数据的一致性。
并行执行的多个事务就像多个线程一起跑任务,每个线程都有对同一块内存块有读取和写入操作。不加任何控制的话,这些所有的操作的执行顺序完全由系统自己控制,可以说是随机的。只要有写入操作就会影响数据的最终状态。系统决定的操作的执行顺序或者说调度(schedule)这个时候是随机的。这个和事务的并发执行其实是差不多的,只是数据库的并发控制器可以去控制这个调度,让最终执行的调度可以满足并行执行的隔离性。接着的问题就是:事务控制器如何制定这个合理的调度。这个合理的调度执行起来要和顺序执行一样,能够保证数据一致。这个「合理」是冲突可串行化。
事务的冲突可串行化
理论上希望事务能够单线程顺序执行,即一个事务执行完再执行下一个事务。但是这不现实,必须要实现事务的并行运行。当事务并行运行,每个事务内又有读和写操作时,如果不增加任何控制,那么可以有任何种情况的执行序列。这样显然是不行,因为只要有事务涉及到写入就会有冲突问题。如果一个事务读一个事务写,先后顺序会影响最终的数据状态。另一种是两个事务都是写,最终哪一个事务写入的数据最终被持久化也是个问题。
既然不能用不加限制的执行顺序来执行事务内的操作,那加上限制就行了。这个限制我的理解是让操作的执行顺序遵守一个预期的准则。如果事务是顺序单线程执行的,比如两个事务 T1 和 T2,先执行 T1 后执行 T2(假设 T1 先到达)。那么并行化以后的执行结果也要和顺序情况下的结果一样才行。为了达到这个目的就需要在并行执行事务的操作的时候,也能控制操作执行的顺序,让他符合这个结果的一致性。
上述的一致性要求书里称为可串行化 ( serializability )。书里是的定义是这么写的:
在并发执行中,通过保证所执行的任何调度的效果都与没有并发执行的调度效果一样,我们可以确保数据库的一致性。也就是说,调度应该在某种意义上等价于一个串行调度。这种调度称为可串行化(serializable)调度。
这个可串行化是针对事务操作的调度来说的。调度是指事务并行运行时,可能发生的一种操作执行顺序(无论如何并行,最终都会显示出一个操作的执行顺序)。比如 T1 > T2 这个事务执行顺序,如果有一个调度 S 能够让运行结果和 T1 > T2 的结果一致,就说这个调度 S 是可串行化的(相对于 T1 > T2 这种串行执行的情况)。
可串行化是事务的并发执行时,操作的调度需要遵守的第一条规则。另外一条是冲突等价。事务内对数据的操作排除 commit 就只有 read 和 write(commit 以后再讨论)两种。两个事务都读那没问题,不会冲突。如果一个至少存在一个写,那就会产生冲突,这个前面已经提过。一个调度内不冲突的操作是可以互换位置的,比如对一块数据的多次读取并且没有写入,操作顺序随便换也不会影响数据的一致性,又比如对不同部分的数据只进行写入,也不影响。如果一个调度将其中不会产生冲突的操作更改了顺序,那这个新的调度和更改之前的调度称为互为冲突等价的。再由这个定义引出冲突可串行化的概念:如果一个调度是可串行化,并且相对真正串行化执行事务的调度是冲突等价的,那么就说这个调度是冲突串行化的(conflict serializability)。
说了这么多,那么为什么需要这个冲突串行化概念呢?我的理解是:如果数据库接收到两个事务,他可以按照冲突串行化的规则确定出有哪些可串行化调度可用,这个调度中哪些操作是冲突的需要严格控制执行顺序的,哪些操作是互相不冲突可以并行执行的。这样就达到了即使并行执行,也能保证像顺序单线程执行一样的效果,同时并行执行还能提升性能。(有可能是错的,日后回来更新)
如何检验一个调度是否是冲突可串行化的
比如说有个 3 个事务T1 T2 T3,每个事务都有各自的读或者写操作。先定义一种事务执行的顺序关系,这个关系是这样的:
如果两个事务(T1 T2)有在同一块数据上执行互相冲突的操作,比如 T1 有一个 write(Q), T2 有个 read(Q) 。如果 S 是 T1 和 T2 的一个调度,并且这个调度中 T1 的 write(Q) 先于 T2 的 read(Q) 执行,就说 T1 -> T2,反过来就是 T2 -> T1。
如果有好多个事务,比如 T1 T2 T3 T3,如果事务之间有存在互相冲突的操作。就可以以这些事务为节点,构建一个有向图。就像这样:
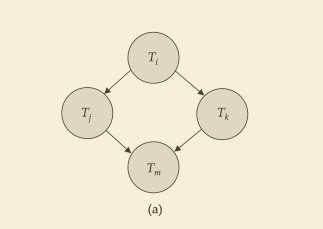
那么可以定义:如果这个有向图是无环的,就可以证明这个调度是冲突可串行化的。
以上是理论上判定调度是否冲突可串行化的方法,书上更多把他拿来作为描述问题的工具,真正的现实数据库好像没有使用这个算法。
那为什么有向图中无环了就冲突可串行化了呢。其实 T1 -> T2 表示的是最终事务的逻辑执行顺序,事务虽然是并行执行,但是至少最终数据的执行结果要是和串行执行一样的。并行执行的事务其实也保证了事务逻辑执行的顺序,T1 -> T2 就是这个顺序。如果有环其实就是矛盾了,因为在顺序执行时一定是一个事务在前或者一个事务在后。并行执行下,如果冲突的数据操作呈现的最终执行顺序如果一会儿是正序,一会儿是反序,就不对了。违反了可串行化,也违反了冲突等价。
一些资料:
中文资料,比较好阅读:http://blog.csdn.net/yueguanghaidao/article/details/6761540
比较全的英文资料:https://www.geeksforgeeks.org/precedence-graph-testing-conflict-serializability/
DAG:http://www.cnblogs.com/en-heng/p/5085690.html
如何实现隔离性
或者说如何实现冲突可串行化。第一种是用锁来实现。
共享锁、排他锁,相容性
死锁
防止锁饿死(starved)
有了锁的基础概念和认识后,真正用锁实现冲突可串行性的实现方法有哪些?
两阶段锁:防止级联回滚、严格两阶段锁、强两阶段锁(附锁的升级和降级),对数据统计在初始阶段加锁,结束阶段解锁,避免死锁同时保证冲突可串行性。
以上一些比较好理解,就暂时不重新描述了
实现锁的数据结构:hash表(锁表),非常像 Jdk HashMap 的结构。
第二种:基于图的协议 … TODO
分粒度的锁
看写的另一篇文章:
http://footmanff.com/2018/01/17/2018-01-17-multiple-granularity-locking/
一些资料:
http://www.edugrabs.com/multiple-granularity/
快照隔离
SQLServer、PostgreSQL、Oracle 使用的并发控制技术 TODO
插入、删除、和谓词读
这个应该和 MySQL 的 gap lock 有关。http://footmanff.com/2018/01/30/2018-01-30-predicate-read-and-mysql-gaplock/
索引封锁(index-locking)和间隙锁的关系,书中的理论如何和何登成的文章对照理解。
一个问题:间隙锁和排他锁会互相冲突吗?
其他资料
官方关于锁的文档:
https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html
何登成写的文章:
数据库系统概念 第六版
数据库系统实现 第二版